
Article written on June 30st 2025
A Technical Deep Dive into ACT, GR00T, and How to effectively collect a lerobot dataset
The promise of foundation models in robotics is enormous: instruct a robot in natural language, and watch it perform a task. With state-of-the-art tools seemingly making this more accessible than ever, I aim to take on a project to test what it takes to get a simple pick-and-place task working. The goal is straightforward: collect a dataset and train two different Vision-Language-Action (VLA) models, ACT and GR00T N1, to have a robot arm “pick the green earplug outside the container and put it inside the container.”
I used the user-friendly GUI from Phosphoai, which simplifies the process of data collection, training, and deployment. The experience taught me the critical, often-overlooked technical details that can make or break a robotics project.
Part 1: The Setup – Data Collection is Key
Before any model can learn, it needs data. My first step was to create the “earplugs_new dataset“. Using imitation learning, I teleoperated a so-101 robotic arm to perform the task repeatedly. Here’s a look at the process:
- The Task: A simple pick-and-place operation.
- The Process: I collected 65 episodes which took about 45 minutes of recording time, not including the initial setup. The video of the process gives a realistic sense of the time investment required for even a simple task. On top of this, the dataset was balanced and diverse, with different positions of container, earplug and initial robot location.
- The Environment: A crucial lesson from the start is the importance of a controlled environment. My goal was to have everything except the robotic arm remain static. I improvised a background and ensured lighting conditions were constant to avoid introducing unwanted variables for the model to learn from. A good rule of thumb is to set up your cameras so that you could perform the task yourself just by looking at their feed.
- The Format: The data, including motor states and actions, was collected and stored on Hugging Face in the
Lerobot v2.1format, a standard that makes it easy to share and use datasets within the community. The dataset includes images from a main context camera and a secondary wrist camera.
Part 2: Training the Models – two Architectures
With the dataset ready, it was time to train the models. Phopshoai, again, provides all the necessary tools to train the models from their user interface. I chose two models with fundamentally different philosophies.
ACT: The Lean, Task-Specific Imitator
Link to the original paper: https://arxiv.org/pdf/2304.13705
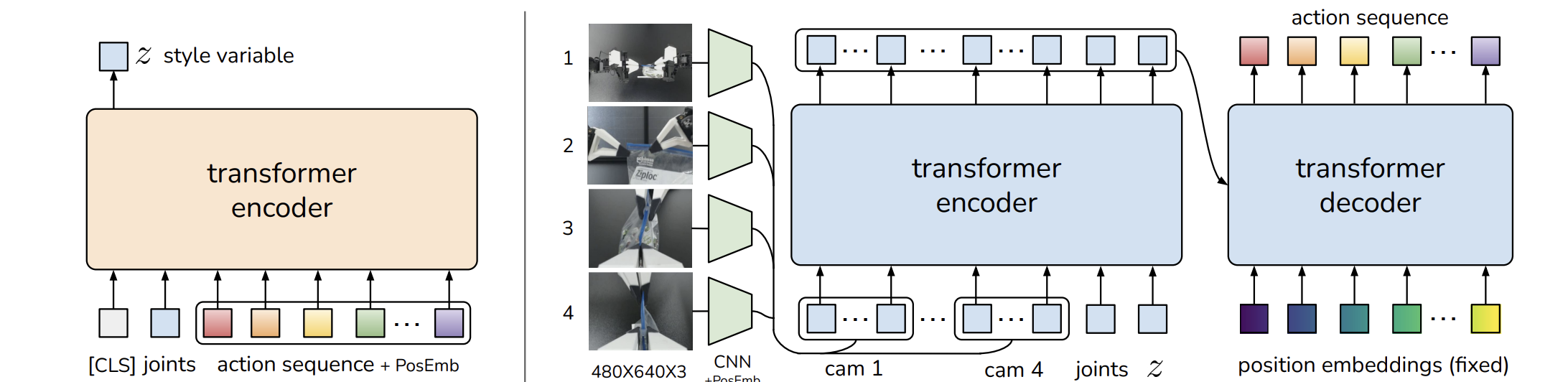
ACT (Action Chunking with Transformers) is an imitation learning algorithm designed specifically to combat the “compounding error” problem where small mistakes accumulate over time. Its core technical innovations are:
- Action Chunking: Instead of predicting one action at a time, it predicts a sequence of k future actions at once. This reduces the effective horizon of the task by a factor of k, mitigating error accumulation and helping model non-Markovian behaviors (like pauses) often found in human demos.
- CVAE Architecture: It’s implemented as a Conditional Variational Autoencoder (CVAE). This allows it to model the variability and multi-modality inherent in human demonstrations.
- Structure: It’s a relatively compact model at ~80 million parameters. It uses a Transformer encoder-decoder. Image observations are first processed by ResNet backbones, then concatenated with robot joint positions. This combined data is fed to a Transformer encoder, and a separate Transformer decoder generates the final action sequence. It is trained from scratch for each specific task.
I trained ACT with the following hyperparameters:
- Batch Size: 60
- Steps: 8000
GR00T N1: The Massive, Generalist Foundation Model
Link to the paper: https://arxiv.org/abs/2503.14734
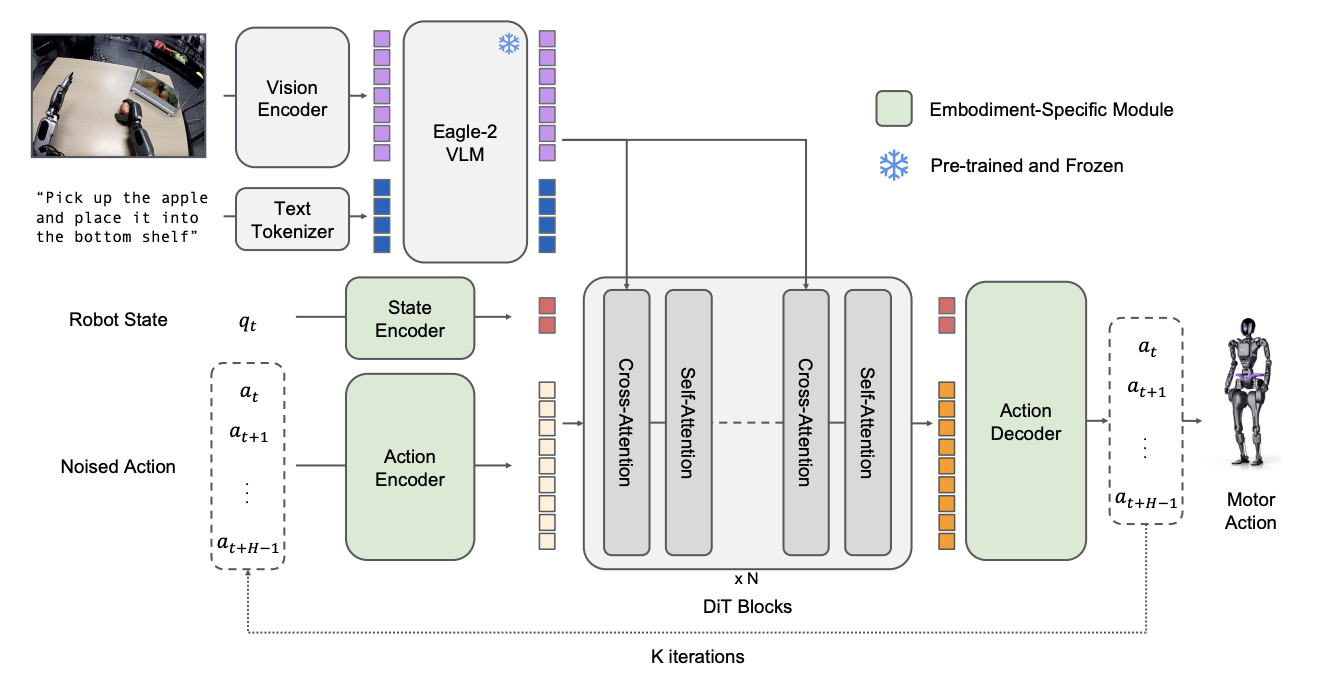
Developed by NVIDIA, it’s a massive, open foundation model with ~2.2 billion parameters. It wasn’t trained just on my task, but on a vast and diverse “data pyramid” of real robot data, synthetic data, and human videos. Its architecture is a sophisticated dual-system design:
- System 2 (The Thinker): A powerful Vision-Language Module (VLM), specifically NVIDIA’s Eagle-2, which is tasked with interpreting the environment and language instructions.
- System 1 (The Doer): A Diffusion Transformer (DiT) that serves as the action module, generating fluid, real-time motor commands by using a technique called flow-matching.
I fine-tuned GR00T N1 using these parameters:
- Batch Size: 49
- Epochs: 10
- Learning Rate: 0.0001
Part 3: Inference
After training, I deployed both models. The results were, to be frank, “not good at all”.
- GR00T N1: In one trial, the model managed to pick up the earplug but failed to place it in the container. In another, it couldn’t even manage the initial pick.
- ACT: This model also struggled significantly. It failed to complete the task, and based on community feedback, it likely needed substantially more training steps to achieve reasonable performance.
Part 4: Why Did They Fail?
The failures weren’t random; they were direct consequences of the models’ architectures and the experimental setup.
- The Monochromatic Wrist Camera: A Fundamental Grounding Failure. My prompt was explicit: “Pick the green earplug.” However, the wrist camera—a key sensor for close-up manipulation—provided a black and white image.
- For GR00T N1, a VLA, this is a catastrophic failure of grounding. Its “Language” module (System 2) understood “green,” but its “Vision” module received pixel data with no color information. It was asked to perform an action based on a visual feature that did not exist in its sensory input.
- For ACT, while not a VLA, this is still problematic. The visual features it learns from the black-and-white camera are less rich and distinctive than color features, making it harder to differentiate the object from the background, leading to less robust policies.
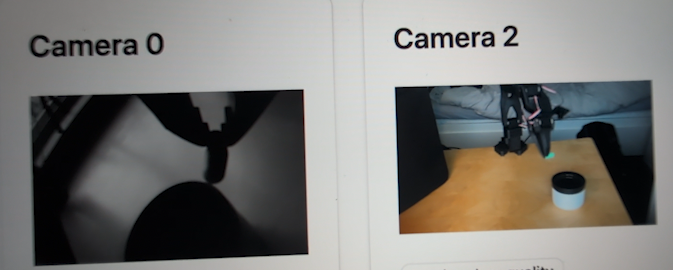
- Model-Specific Flaws:
- GR00T N1’s Data Dilemma: The issue isn’t just that GR00T is big, but what that size implies. A 2.2B parameter model pre-trained on a massive, diverse data pyramid can struggle when fine-tuned on a tiny, 65-episode, single-task dataset. The model’s vast, general knowledge can “overpower” the small amount of new information, leading to poor adaptation. It’s a classic domain shift problem where the fine-tuning data is insufficient to steer the massive model effectively.
- ACT’s Sensitivity: ACT’s smaller size and from-scratch training make it highly dependent on the quality and quantity of in-task data. The ACT paper itself shows that its performance improves drastically with a larger action chunk size (k) and that it can still suffer from compounding errors. My 8000 training steps were likely not enough for the model to learn a robust policy from the limited demonstrations.
Part 5: The Path Forward: exploring other models
Could newer models solve these specific technical issues?
SmolVLA: The Efficient and Responsive Contender
The link to the paper: https://arxiv.org/html/2506.01844v1
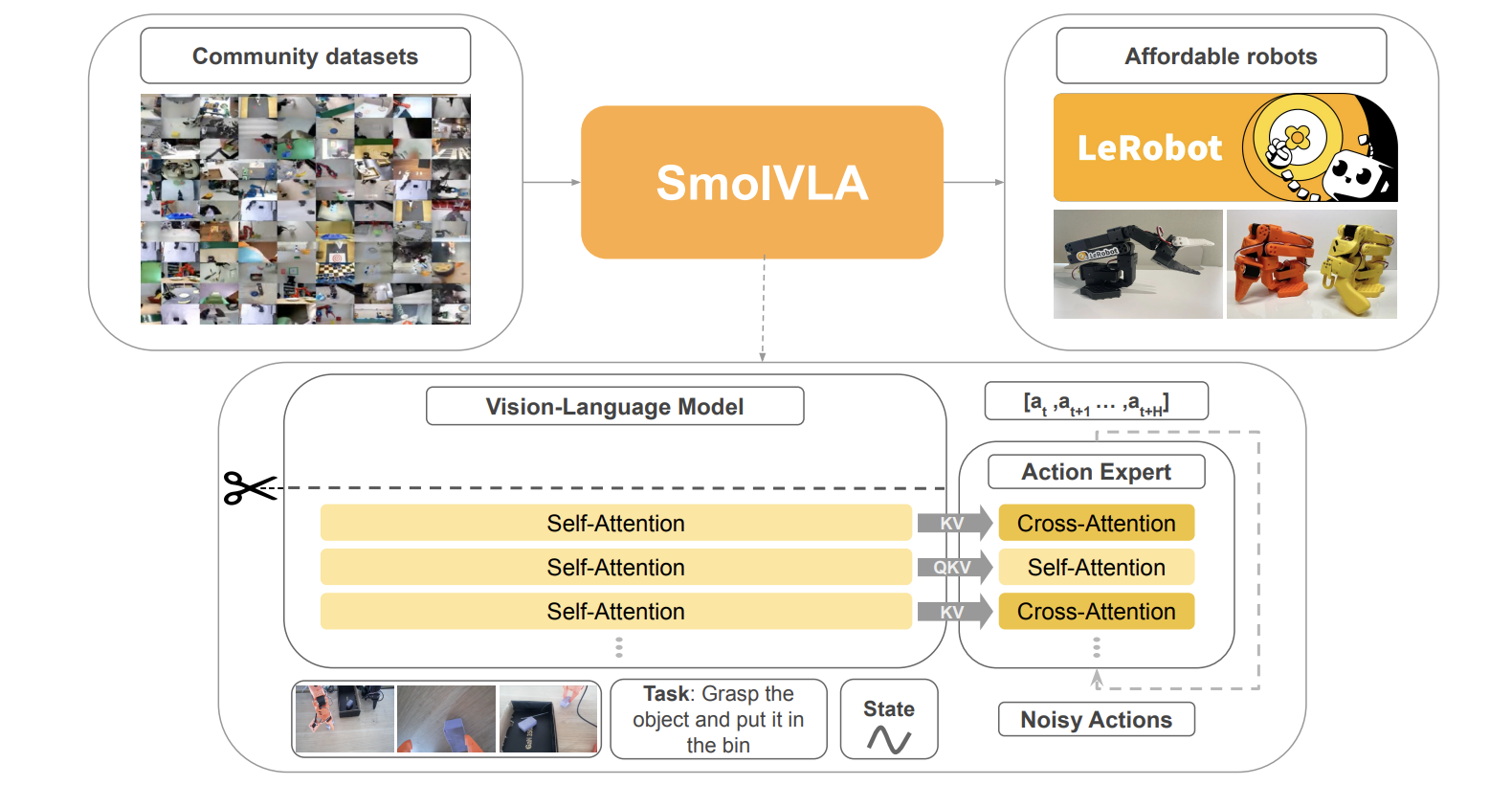
SmolVLA is a VLA designed for efficiency and accessibility.
- Technical Comparison:
- Architecture: Unlike ACT’s from-scratch training or GR00T’s massive scale, SmolVLA takes a hybrid approach. It uses a pre-trained VLM but makes it efficient by skipping the final layers of the LLM backbone, using only features from the first half. Its “Action Expert” uses an interleaved cross-attention and self-attention design that is more lightweight than a full decoder.
- Inference: Its key feature is an asynchronous inference stack. The robot can execute an action from a queue while the policy, potentially on a remote server, computes the next chunk of actions.
- How It Would Translate Experimentally:
- Overcoming “Undertraining”: At under 0.5B parameters and designed for single-GPU training, SmolVLA would have allowed for dramatically faster training cycles. I could have experimented with far more steps and hyperparameters, likely solving the “undertraining” issue.
- Smoother, Faster Execution: Asynchronous inference is a game-changer for robot responsiveness. The paper shows it leads to a ~30% faster task completion time and allows the robot to complete more than twice the number of tasks in a fixed period by eliminating the lag where the robot stops to “think”. This would result in much smoother and less jerky motion than I observed.
- The Camera Problem: SmolVLA is still a VLA. Its performance hinges on its VLM backbone understanding the scene. The fundamental grounding failure from the monochromatic camera would persist. It cannot solve a hardware problem with software alone.
GR00T N1.5: The Data-Efficient Successor
Link to the official release website: https://research.nvidia.com/labs/gear/gr00t-n1_5/
NVIDIA’s GR00T N1.5 is a direct successor to N1, designed to fix its biggest shortcomings.
- Technical Comparison:
- Data Efficiency: N1.5 was explicitly designed to excel in low-data regimes. In simulation benchmarks, it shows a 2.3x performance improvement over N1 when fine-tuned with only 30 demonstrations.
- Language Grounding: It uses an enhanced (and frozen) VLM backbone and a new training objective called
FLARE(Flow-Matching Latent Action Representation) to better learn representations from human videos and align them with language. This has resulted in the language-following success rate on a real robot jumping from 46.6% (N1) to 93.3% (N1.5). - Synthetic Data: It integrates
DreamGen, a video generation pipeline that can create diverse, counterfactual training data from just a few starting frames.
- How It Would Translate Experimentally:
- Solving Data Scarcity: GR00T N1.5’s superior data efficiency means it would have likely performed dramatically better with my 65-episode dataset, directly addressing the core fine-tuning problem I faced.
- The Camera Problem (Revisited): While
FLAREand the better VLM improve language understanding, they can’t invent color information that isn’t in the input pixels. N1.5 would still struggle with the prompt “pick the green earplug” due to the hardware limitation. However, its improved intelligence means I could perhaps try to give it a color-agnostic prompt(at inference) like “pick the earplug on the left” and expect it to succeed.
Final Thoughts
Details matter immensely. State-of-the-art models are not magic; their success is a product of architecture, training data, and—critically—the physical hardware and setup.
I hope to convey that these models are not yet at the point where they can work straight out of the box. They need careful fine-tuning, and even then, they may not look like the fancy demos showcased by the big research labs creating these models.
The key takeaway is clear: A model is only as good as the data it receives. Additinally, keep the data somehow similar to how inference will look like. It will make your life much easier, and will require less troubleshooting and data.
Leave a Reply